The Ultimate Guide to Scraping X (Twitter) in 2026: No API Key, No Code, No Limits
In the fast-paced digital landscape of 2026, data is more than just information—it’s the fuel for innovation. X (formerly Twitter) remains the world’s most significant real-time “town square,” hosting critical conversations on everything from global politics and financial markets to the latest AI breakthroughs.
However, for developers, researchers, and marketers, accessing this data has become a Herculean task. The official X API has evolved into an expensive, restricted, and complex gatekeeper. But what if you could bypass the red tape and extract thousands of tweets with a few clicks?
Enter the X (Twitter) Advanced Search Actor—a game-changing solution designed for the modern data era. In this guide, we’ll show you how to master Twitter scraping in 2026 without writing a single line of code or paying for a $5,000/month API subscription.
If you also need follower graph analysis, read our companion article on the X (Twitter) Followers Scraper. If the question is account visibility rather than bulk tweet extraction, use the Twitter shadowban checker workflow. For the broader project index behind these scraping tools, see the Apify API Actors page.
The X API Crisis: Why You Need an Alternative
For years, the official API was the standard way to interact with Twitter data. Today, it’s a bottleneck. If you’re looking for an X API alternative, here’s why the official route is often a dead end:
-
Prohibitive Pricing: With enterprise tiers often starting at $5,000/month, the API is priced for corporations, not individuals or growing startups.
-
Strict Rate Limits: Even at high price points, you’re often limited by how many tweets you can fetch per month or per hour, making large-scale research impossible.
-
Complex Approval Processes: Getting an API key requires lengthy applications and strict use-case justifications.
-
No “No-Code” Support: The official API requires technical expertise to implement, maintain, and scale.
The X (Twitter) Advanced Search Actor eliminates these barriers. It operates as a professional-grade web automation tool that retrieves data just like a human would—only thousands of times faster.
Why This Actor is the Best Twitter Scraper in 2026
This isn’t just another basic scraper. It’s a sophisticated data extraction engine. Here’s what makes it the gold standard:
1. No API Key or Account Required
You don’t need to worry about being banned, managing tokens, or staying within “v2” or “v1.1” endpoints. The actor handles the hard part of navigating X’s infrastructure for you.
2. Surgical Search Precision
The actor leverages X’s advanced search operators but adds an intelligent layer on top. You can filter by:
-
Engagement Metrics: Find viral content by setting minimum likes (min_faves), retweets, or replies.
-
Media Types: Extract only tweets with videos, images, or specific links.
-
Geographic Data: Target specific cities or a radius around coordinates.
-
Time-Specific Windows: Scrape data from yesterday or from five years ago with equal ease.
3. Intelligent Query Optimization
Under the hood, the actor uses a built-in Query Builder. It automatically optimizes your search terms, groups related keywords, and removes redundant filters. This ensures you aren’t just getting any data—you’re getting the right data.
4. Cost-Effective Scaling
While the official API charges you a flat (and high) monthly fee, the Apify platform uses consumption-based pricing.
-
Scraping 1,000 tweets costs roughly $0.35.
-
Scraping 100,000 tweets costs about $35.00.Compare that to a $5,000/month bill, and the choice is clear.
Step-by-Step Guide: How to Scrape Thousands of Tweets (No-Code)
Ready to start? Follow these steps to build your first dataset in under 5 minutes.
Step 1: Create a Free Apify Account
Sign up at Apify.com. You’ll get $5 in free credits immediately, which is enough to scrape thousands of tweets for free and test the tool’s capabilities.
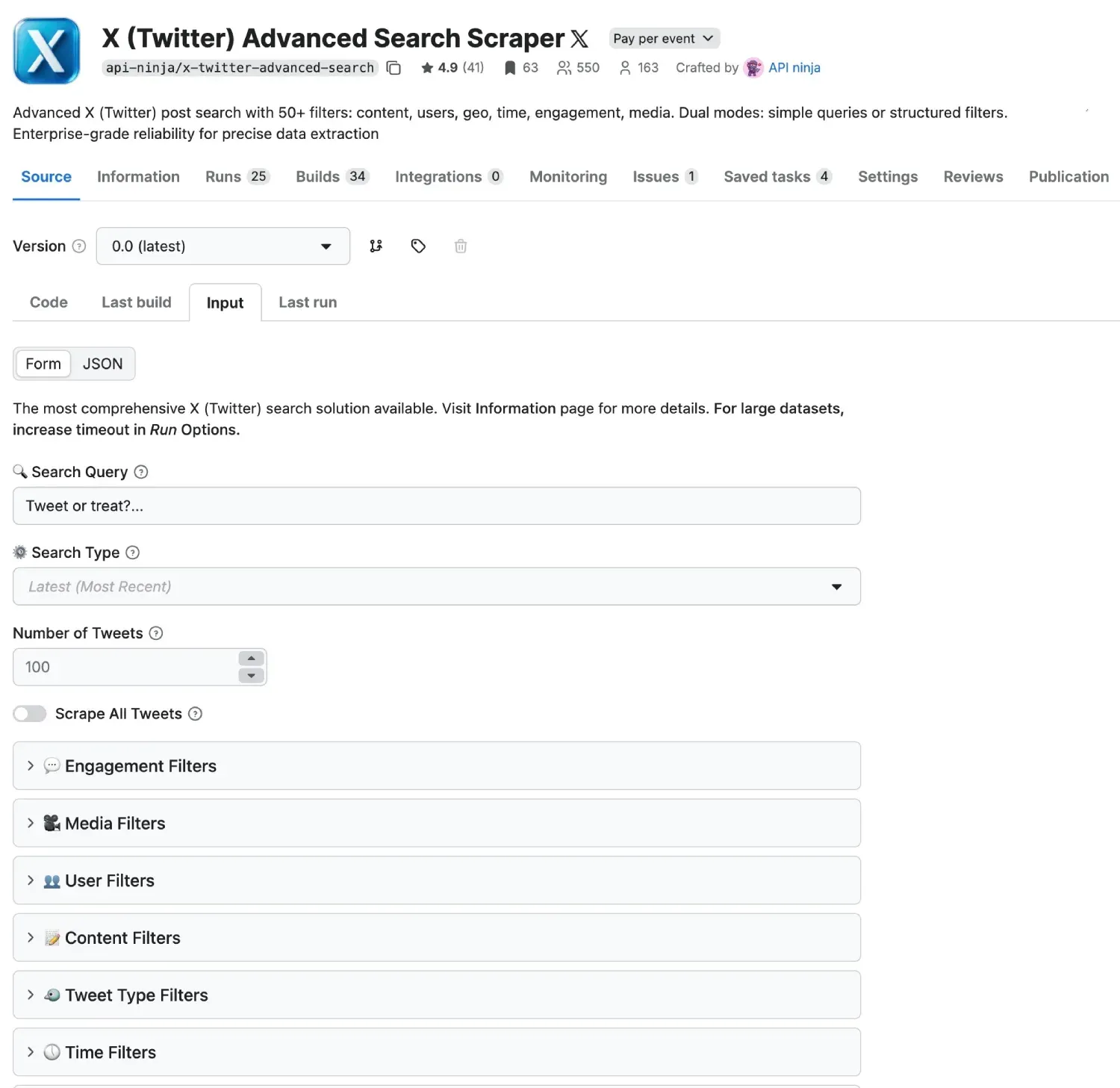
Step 2: Navigate to the X Advanced Search Actor
Go to the X (Twitter) Advanced Search Actor page. Click the “Try for free” button to open the actor’s configuration console.
Step 3: Configure Your Search
You have two ways to input your search:
-
Simple Mode: Just type your keywords into the “Query” field (e.g., #Bitcoin since:2026-01-01).
-
Advanced Mode: Use the intuitive form to select specific filters. Want only tweets in English with more than 500 likes? Just toggle the options.
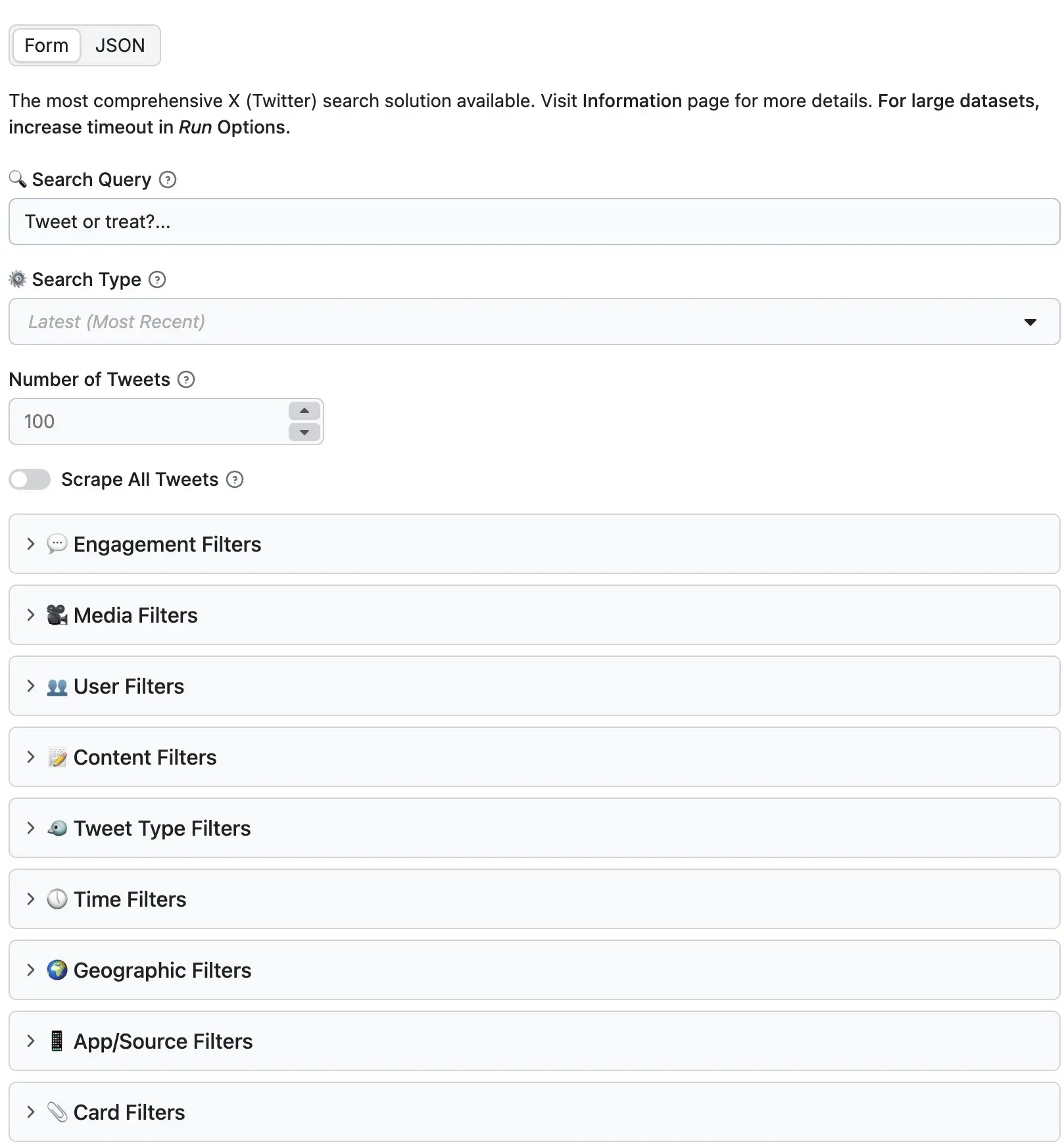
Step 4: Set Your Limit
In the “Number of tweets” field, enter how many results you want. Whether it’s 100 or 10,000, the actor will paginate through the results automatically. For massive datasets, you can even enable the “Scrape All” flag.
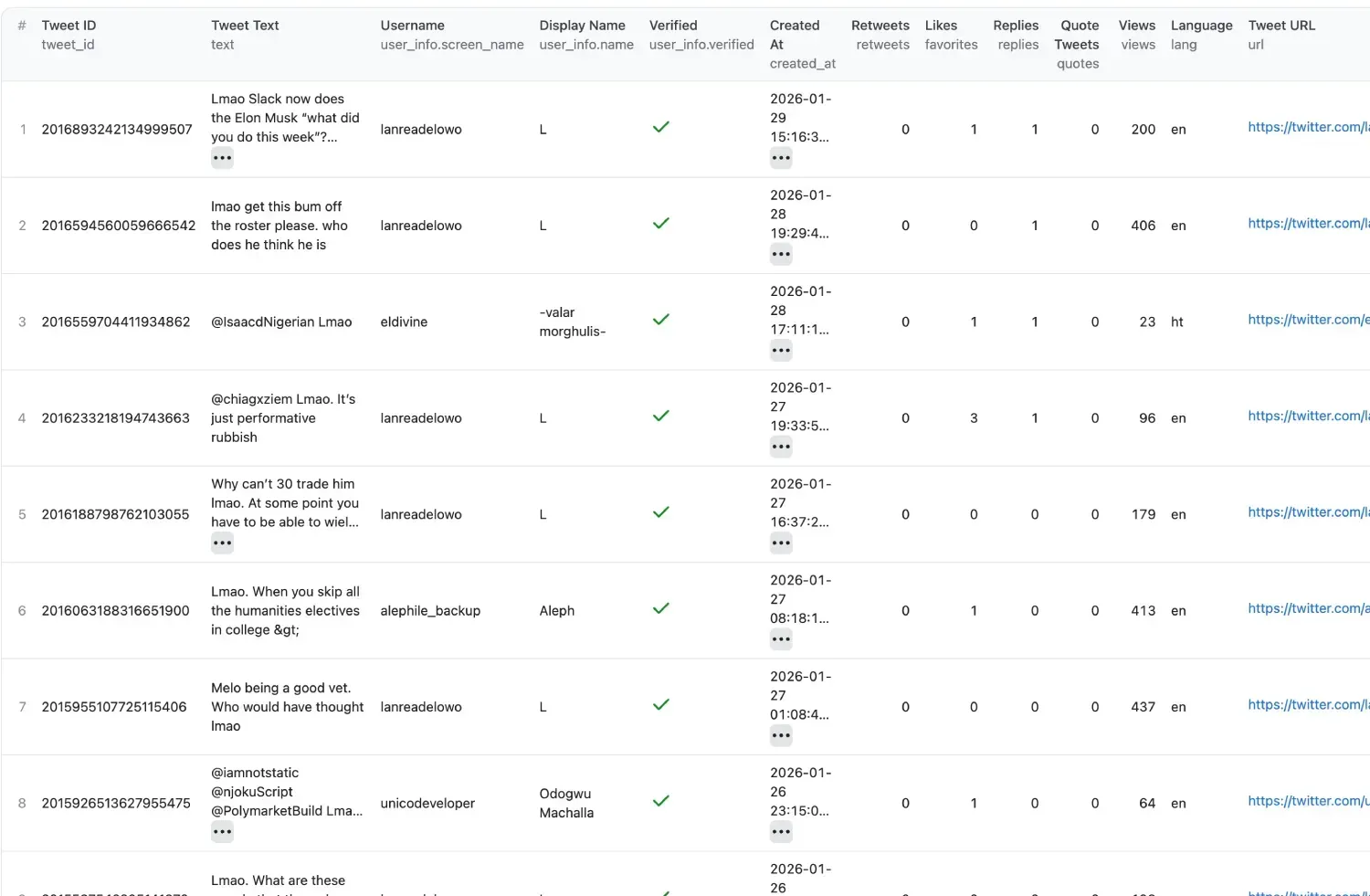
Step 5: Run and Export
Click “Start”. Watch the logs as the actor finds and collects tweets in real-time. Once finished, you can download your data in CSV, Excel, JSON, HTML, or XML. You can even integrate the output directly into Google Sheets or your own CRM via Webhooks or API.
Expanding Your Toolkit: The Twitter Scraper Ecosystem
While the Advanced Search Actor is the “Swiss Army Knife” of Twitter data, sometimes you need specialized tools. Our suite includes other powerful actors to cover every angle:
🛡️ X (Twitter) Community Search & Post Scraper
Communities are the new hubs of niche discussions on X. Use this specialized tool to scrape posts from specific X Communities that aren’t always indexed in the main search. It’s perfect for sentiment analysis in closed groups or tracking specific hobbyist movements.
👥 X (Twitter) Followers Scraper
Need to analyze an influencer’s audience? The Followers Scraper allows you to export the list of followers (or following) of any public account. This is invaluable for lead generation, competitive intelligence, and identifying key opinion leaders (KOLs) in your industry.
We cover that workflow in detail in Unlock Audience Insights: The Ultimate Guide to the X (Twitter) Followers Scraper.
Other best actors
Real-World Use Cases for 2026
How are people using this data today?
-
AI Training & Fine-Tuning: Large Language Models (LLMs) need clean, human-generated conversation data. This actor provides high-quality datasets filtered to remove bot spam.
-
Market Sentiment: Hedge funds use it to track cashtags like $TSLA or $NVDA in real-time, filtering for “Viral” engagement to spot market-moving news early.
-
Brand Monitoring: Track mentions of your brand across different languages and regions, identifying customer pain points before they escalate.
-
Academic Research: Sociologists use historical filters to study the evolution of public discourse over years of data without needing archival API access.
Conclusion: Data Democratization is Here
The days of paying thousands of dollars for basic data access are over. Whether you’re a solo researcher or an enterprise-level data scientist, the X (Twitter) Advanced Search Actor gives you the power to see the whole picture of what’s happening on X.
Stop fighting with API limits and start getting insights.
If you are evaluating agent-oriented alternatives to scraping actors, the perfect backend for AI agents article is the closest internal comparison.
👉 Start Scraping X (Twitter) for Free Now
Disclaimer: Using these tools responsibly is the user’s responsibility. Ensure your data collection practices align with ethical standards and legal requirements.
Frequently Asked Questions
Can I scrape X (Twitter) without using the official API?
Yes. This workflow uses a managed actor on Apify to collect publicly available data without API keys.
How much does scraping cost compared to the official API?
Costs depend on run size, but for many use cases it is dramatically cheaper than enterprise API tiers.
Can I automate recurring runs?
Yes. You can schedule actor runs and export datasets to CSV, JSON, or downstream automation flows.
~Max Dziura